Efficient Estimation Of word Representations In Vector Space
Abstract 提出两个通用模型在超大的数据集上面计算词的连续的向量表示。
INTRODUCTION
在大数据上面使用简单的模型可以获得比较好的结果,但是对于很多任务来说,拿不到非常多的数据,所以要关注比较高级一点的模型.
文章的目的是介绍可以用来在几亿单词的语料和几百万的词表中训练高质量的词向量表示。
用最近的提出的方法来对结果词向量表示做测量,希望不仅相似的词彼此接近,而且词要有多重的相似性。
NNLM(Neural network language model)模型是一个线性投影层和分线性的隐藏层来学习一个词分布式表示和统计语言模型。
这篇文章是扩展的先用单个隐藏层的神经网络学习一个词向量表示,然后在将词向量用在一个NNLM上面的方法?
对于词向量的评估是使用不同的模型在不同的与语料上面进行训练?
LDA(Latent Dirichlet Allocation)在大型数据集上面的计算量很大。
定义计算复杂度为在整个训练过程中需要接触到的参数数目:$O=ETQ$,E是训练的epochs,T是单词的数量,Q是根据每一个模型架构来定义的。所有的模型都是根据SGD来训练的。
MODEL ARCHITECTURES
NNLM:每次的输入是(N,1-of-V),经过一个投影矩阵变成(N,D),然后变换到隐藏层(N,H),最后再由隐藏层变换到输出(N,V),计算复杂度:$Q=ND+NDH+HV$。根据词频使用Huffman树来对输出进行编码,然后进行hierarchical softmax。主要的计算复杂度来自$NDH$
RNNLM:RNN的计算复杂度是:$Q=HH+HV$,在这个模型里面词向量的维度就是H。同样的,H*V通过Huffman树和hierarchical softmax可以降低到$H×log_2(V)$
并行化训练:为了使用超大的数据,在大型分布式框架DistBelief上面扩展了几个模型这个框架允许相同模型上面的多个副本进行并行,在一个中央服务器上面控制所有并行副本的梯度更新。使用了mini-batch和Adagrad来进行训练。
New Log-linear Models
这种模型的提出,主要是为了降低计算复杂度,神经网络去训练词向量的话,训练时间会比较长!!!!
Continuous Bag-of-Words Model:
用周围的词去预测当前的词
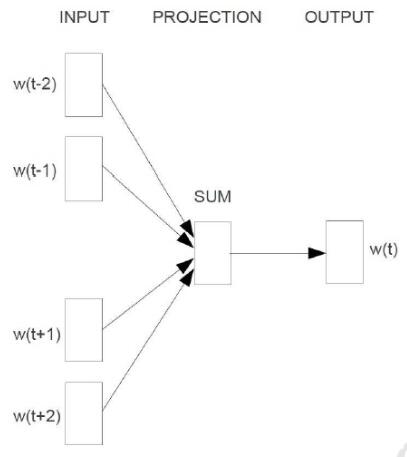
计算复杂度:$Q=ND+Dlog_2(V)$
Continuous Skip-gram Model:
用当前的词去预测周围的词
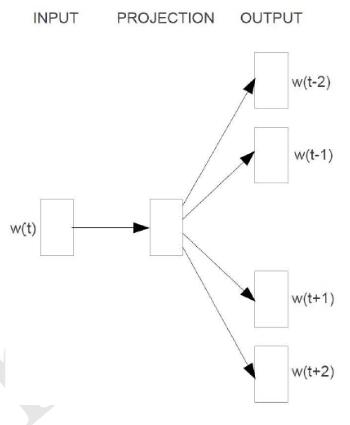
计算复杂度:$Q=C(D+Dlog_2(V))$